
How Structured Logging in Rails Reduced Our Downtime by 98%
Introducing the Five Steps To Observable Software - better understand your Rails app in production whilst slashing time to resolution.

The Problem
The following is based on true story. Names have been changed to protect the innocent.
I'm on call. It's a Friday afternoon and I get a Slack notification:
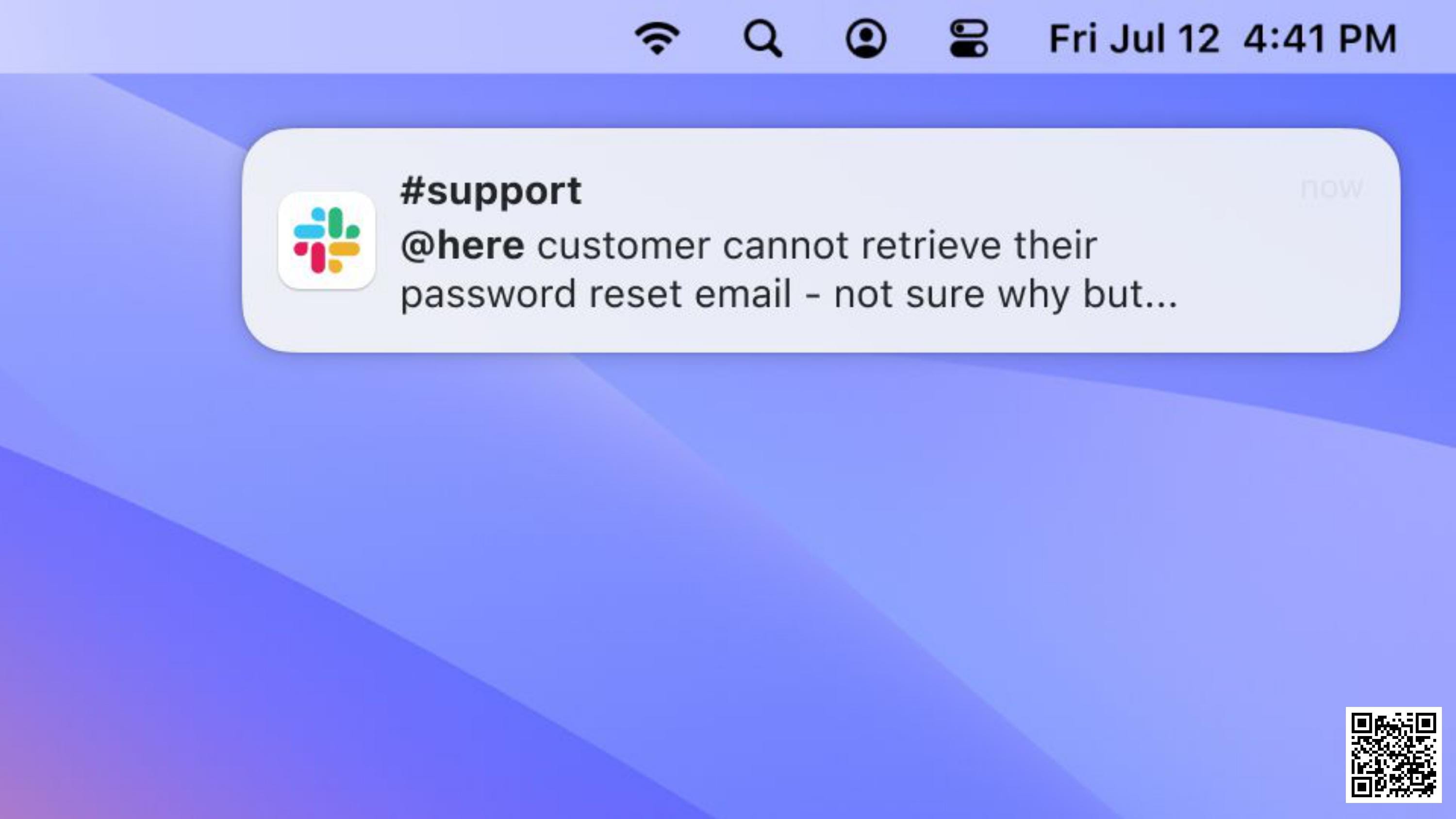
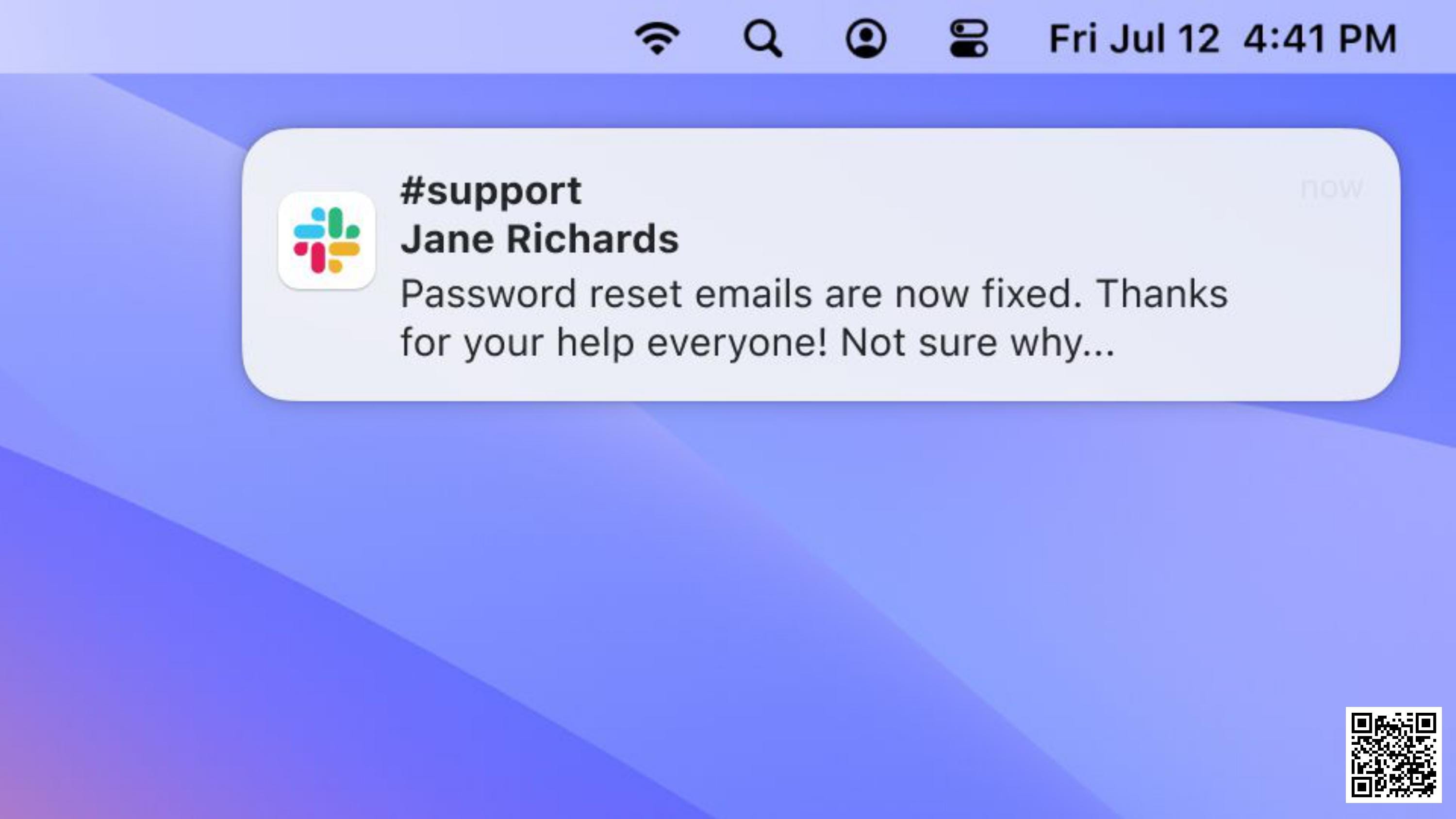
Okay. Looks like password reset emails aren't working:
OK fine, let's go to the logs:
And search them for the job performed event:
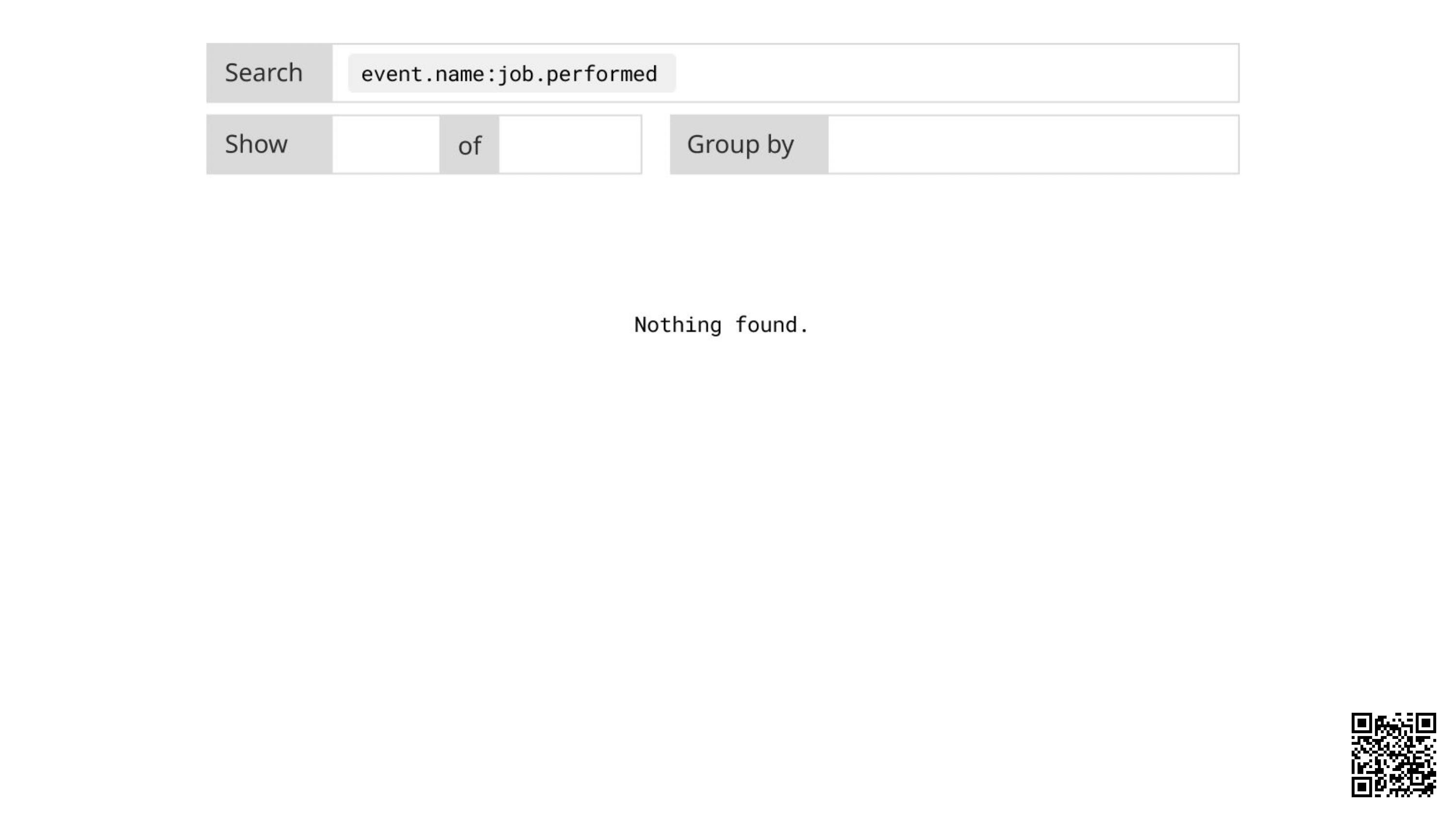
Not that helpful. Well, let's check the code:
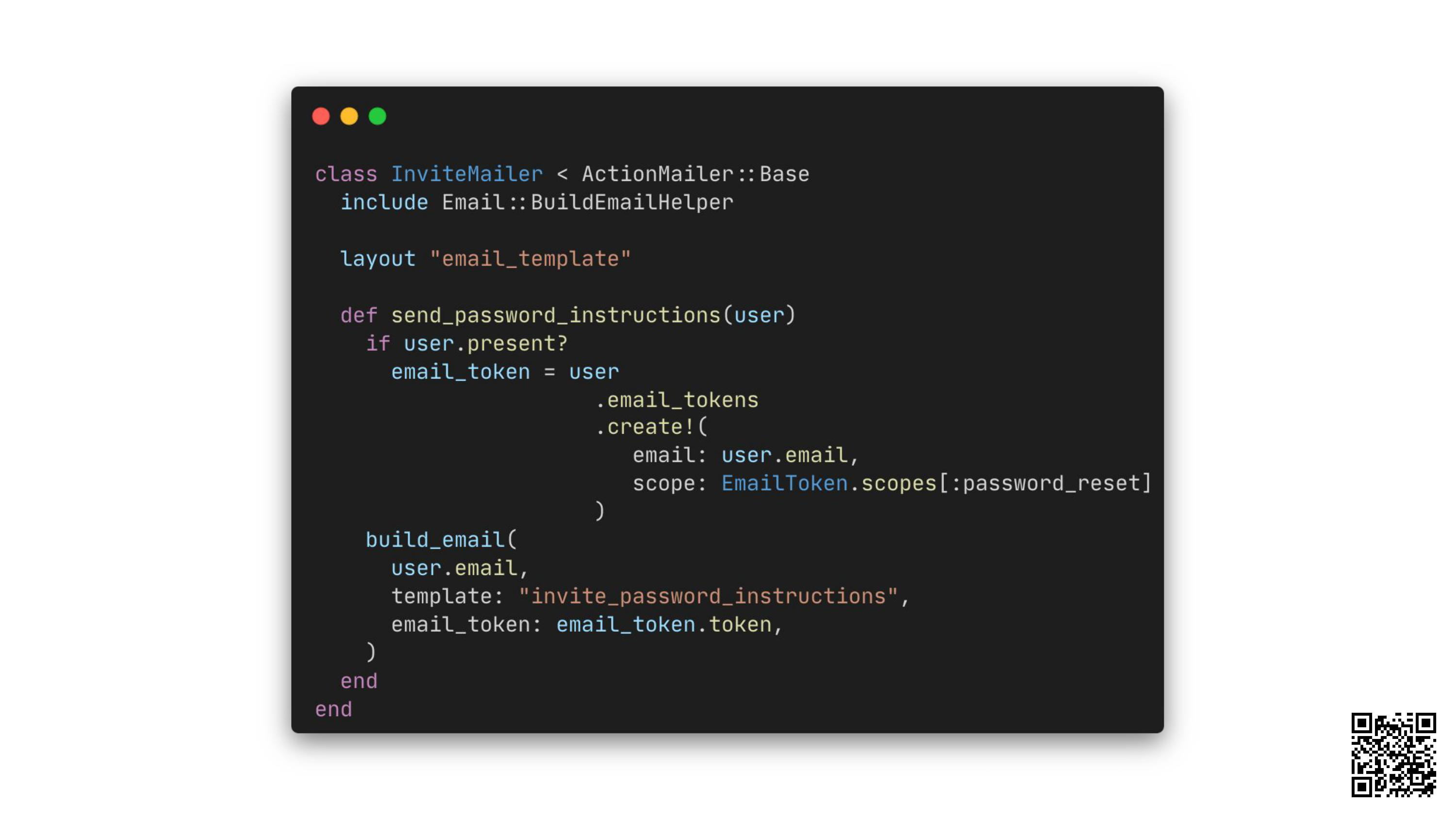
Code looks fine. Which doesn’t really help.
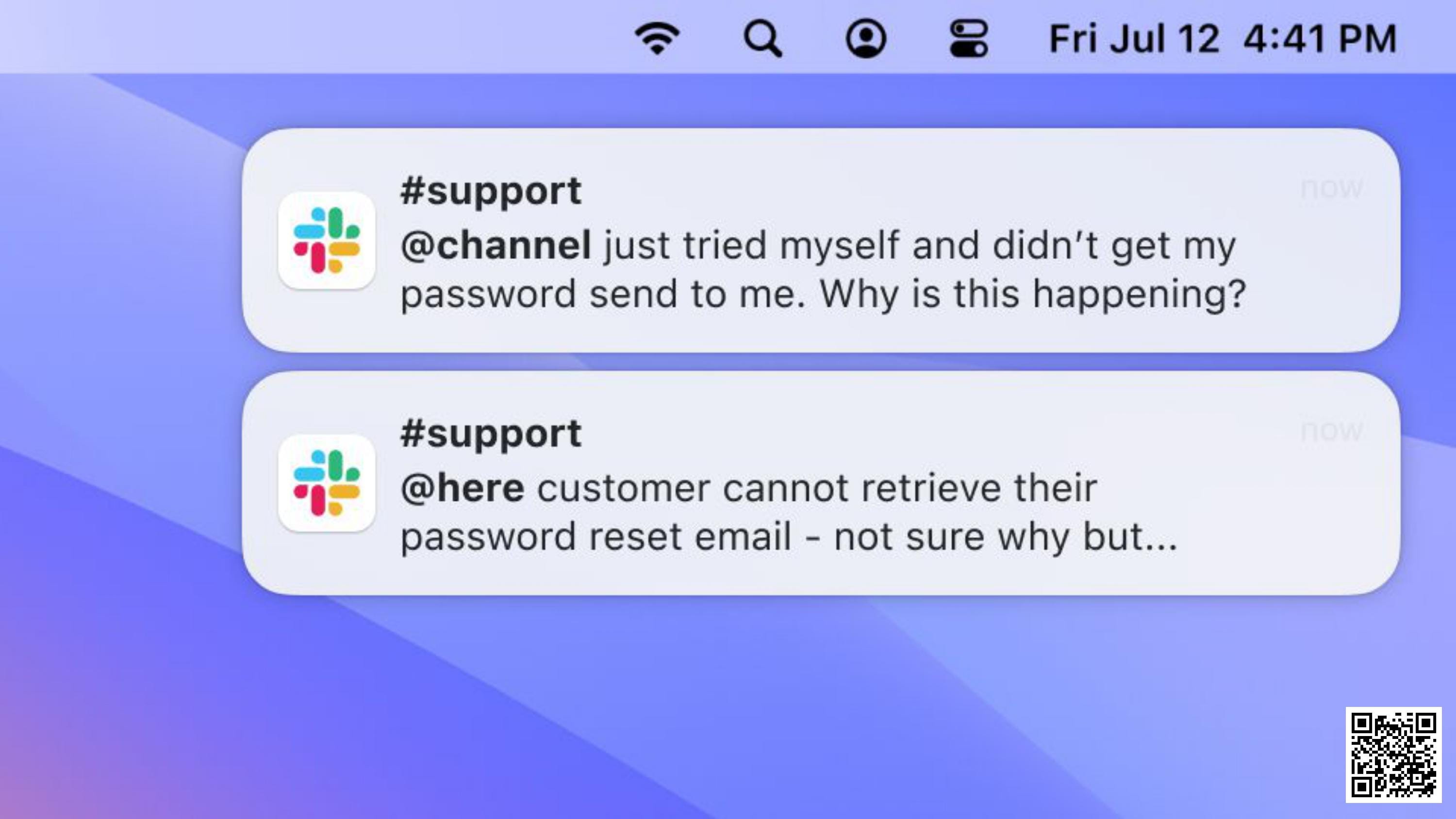
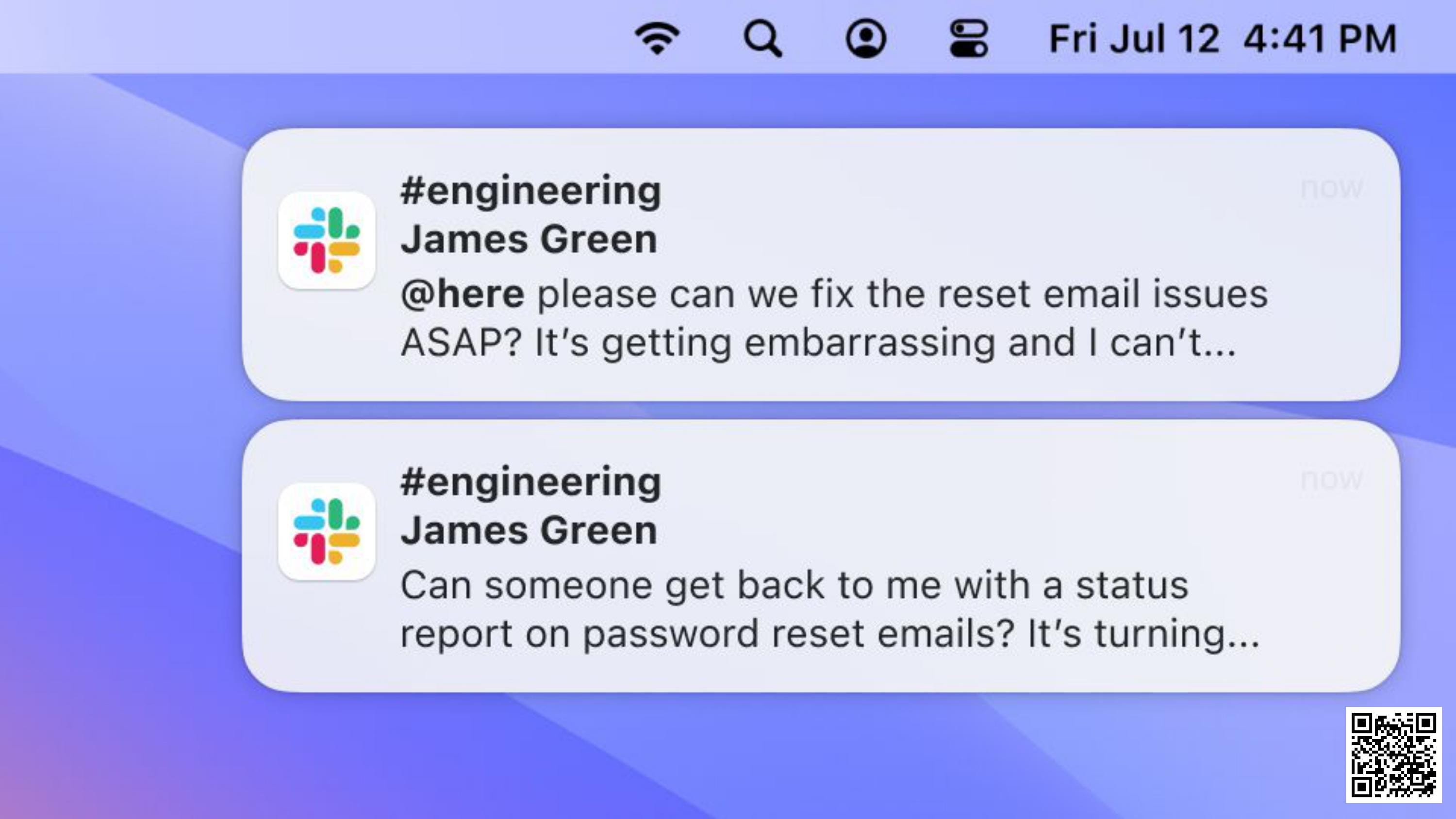
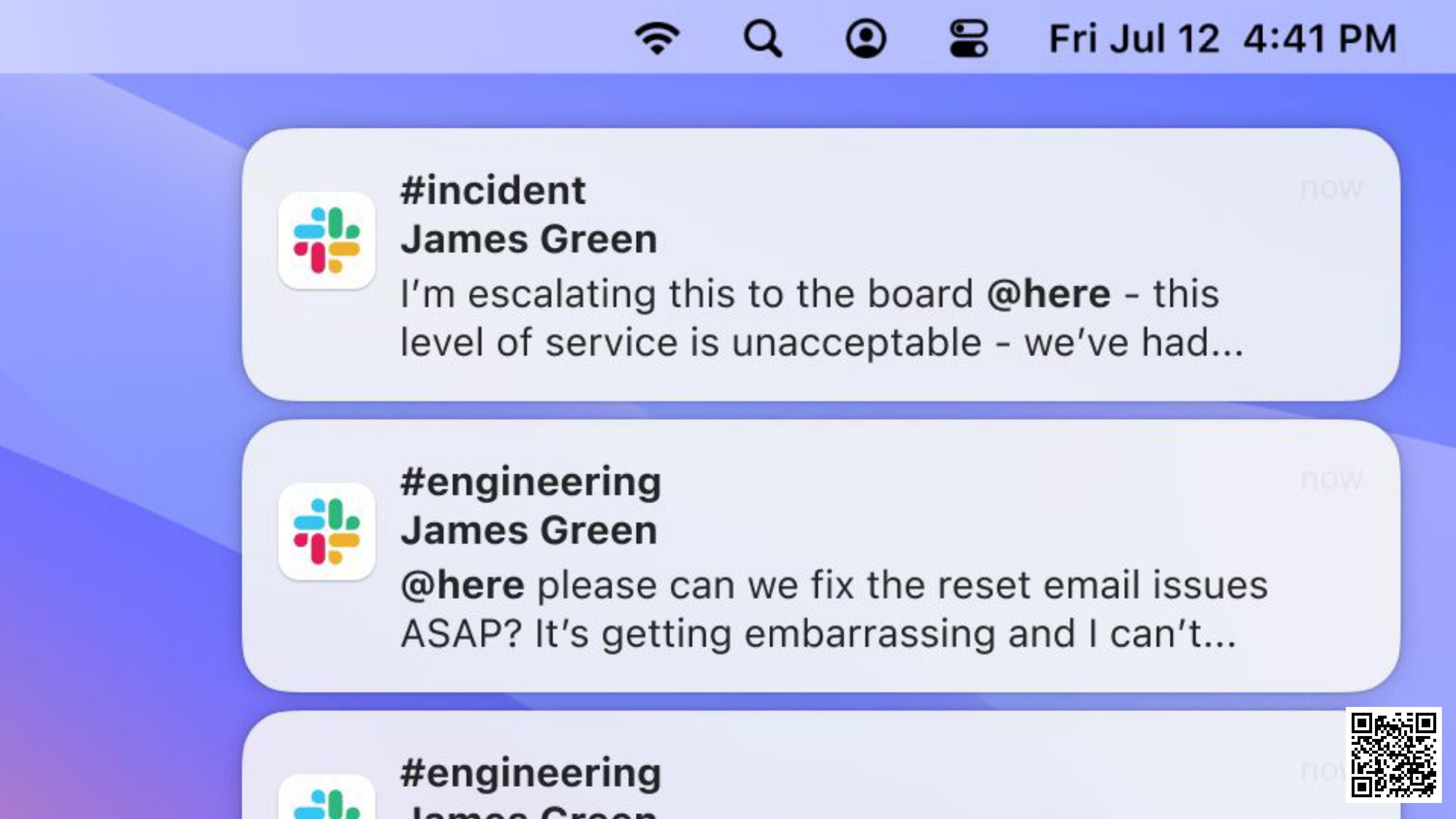
Meanwhile, our CTO is getting anxious:
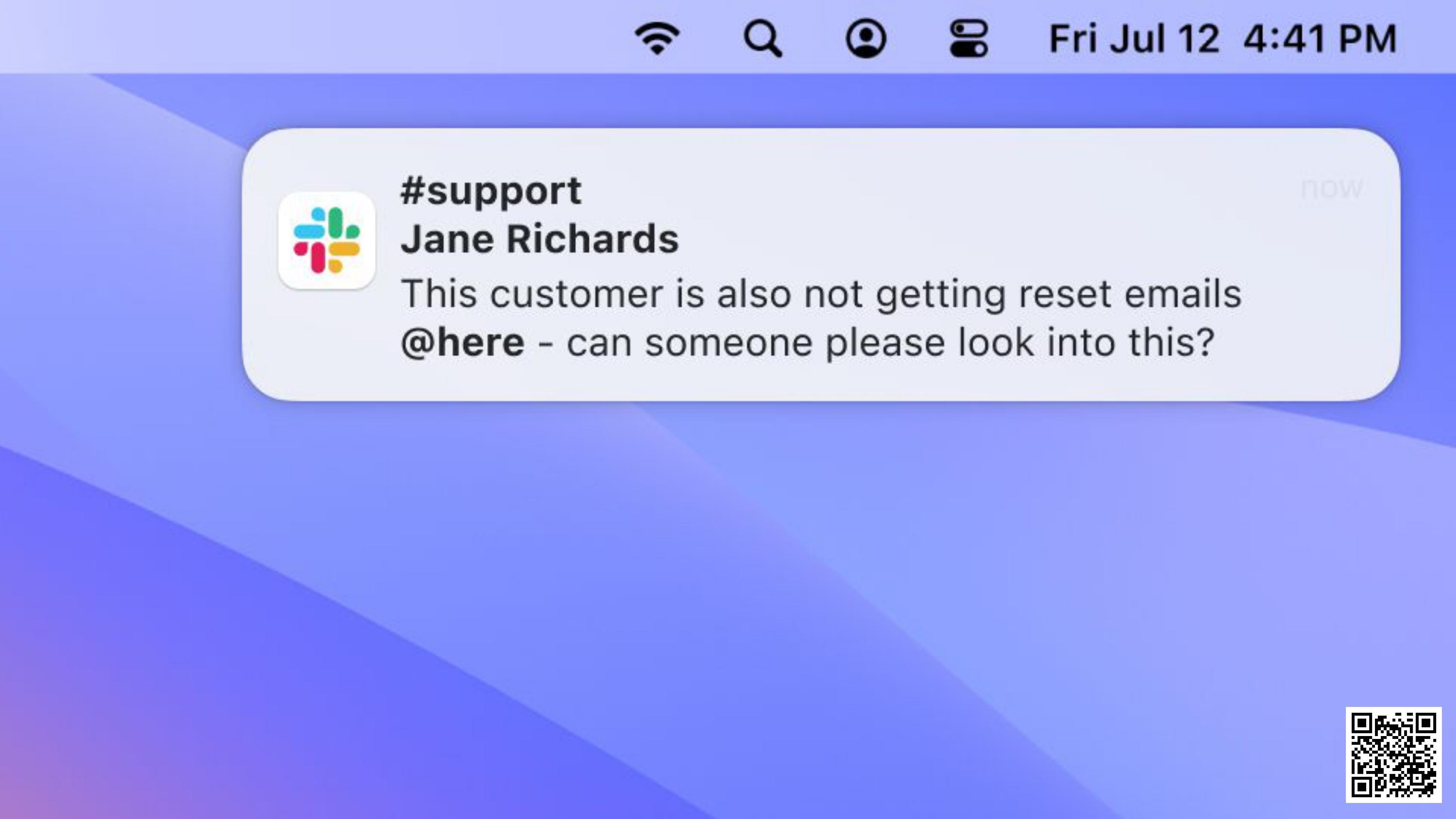
People are taking to Twitter and complaining. Nobody can get into their accounts:
I pair with a colleague and we add error logging.
Whilst waiting for the app to deploy, the issue goes away:
We'll do it later. Put it on the backlog:

Might be a while until we can get to the issue. It’s just a one-off incident though. Right? Right.
Two Months Later
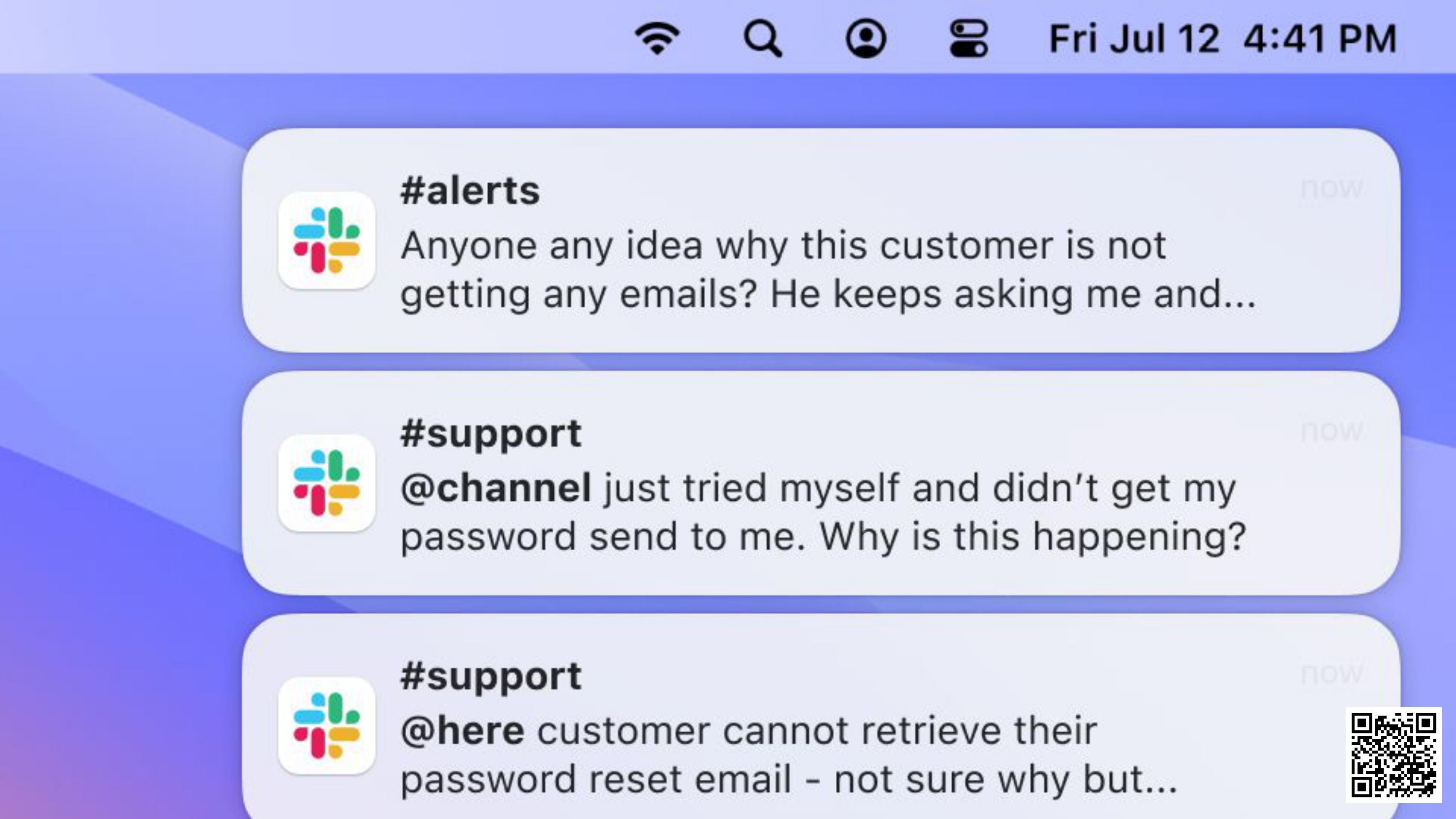
Oh no, it's happening again:
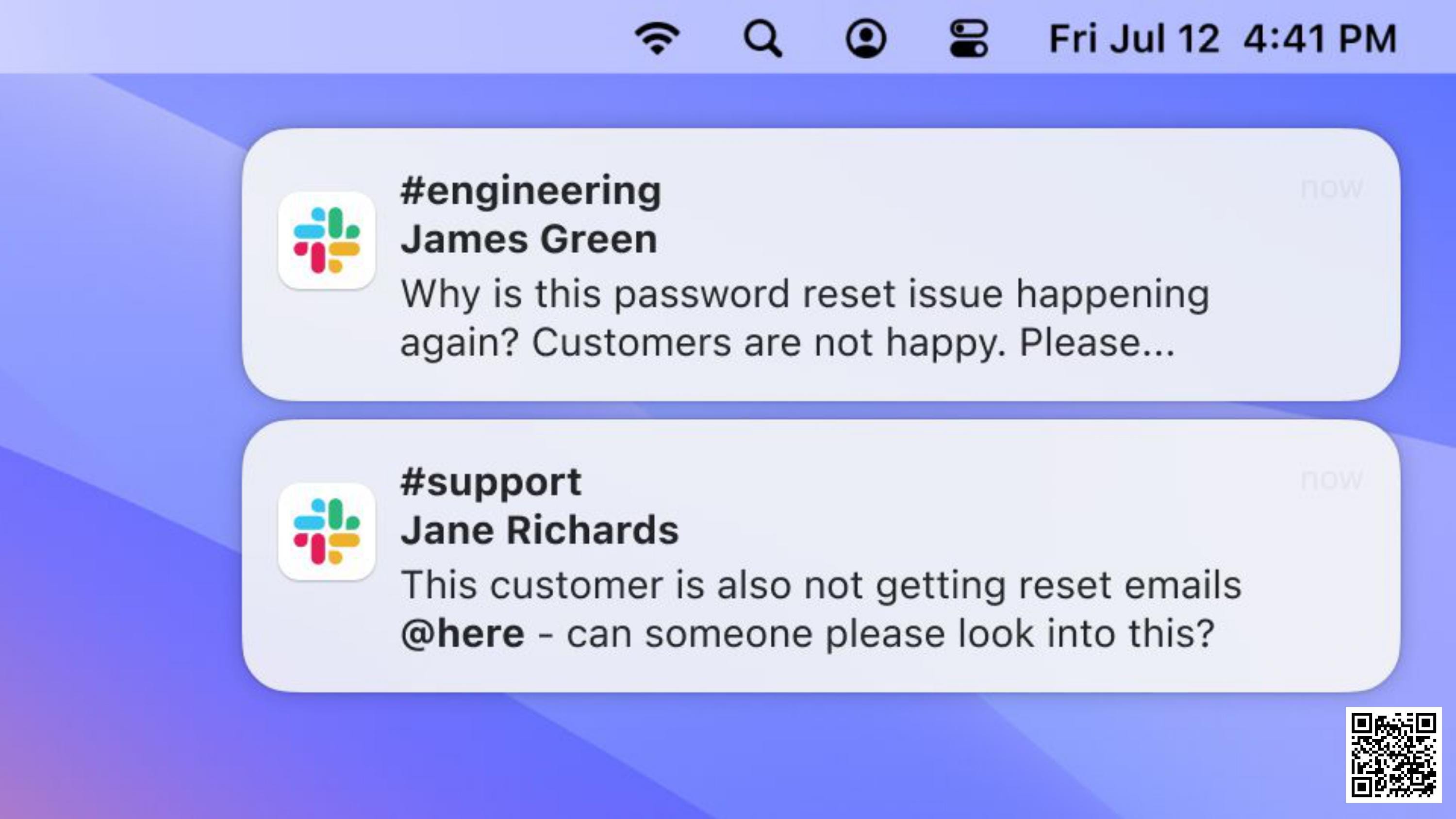
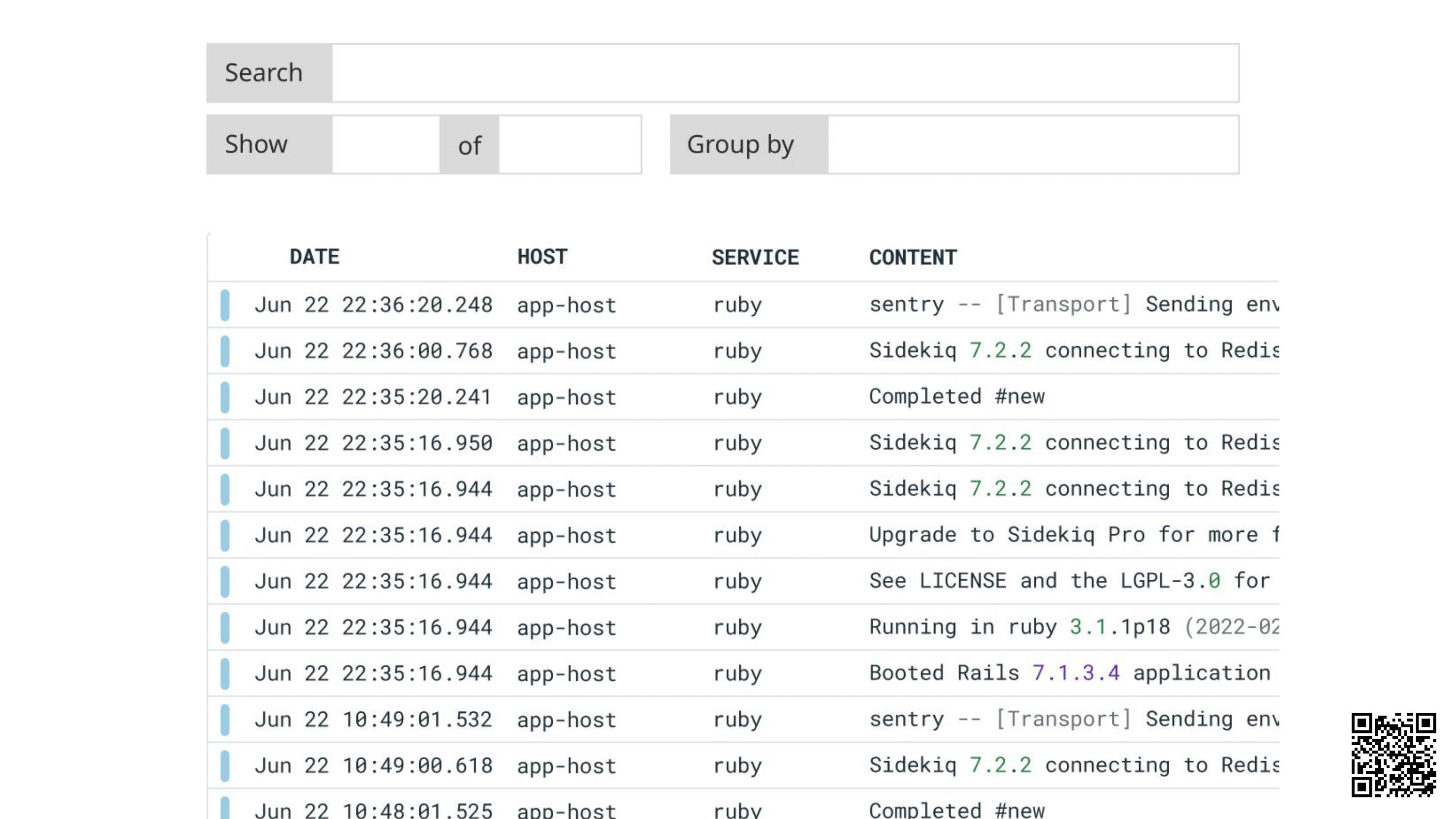
Good job we added the extra logging! We'll search the logs:
Nothing. Open the Sidekiq admin dashboard:
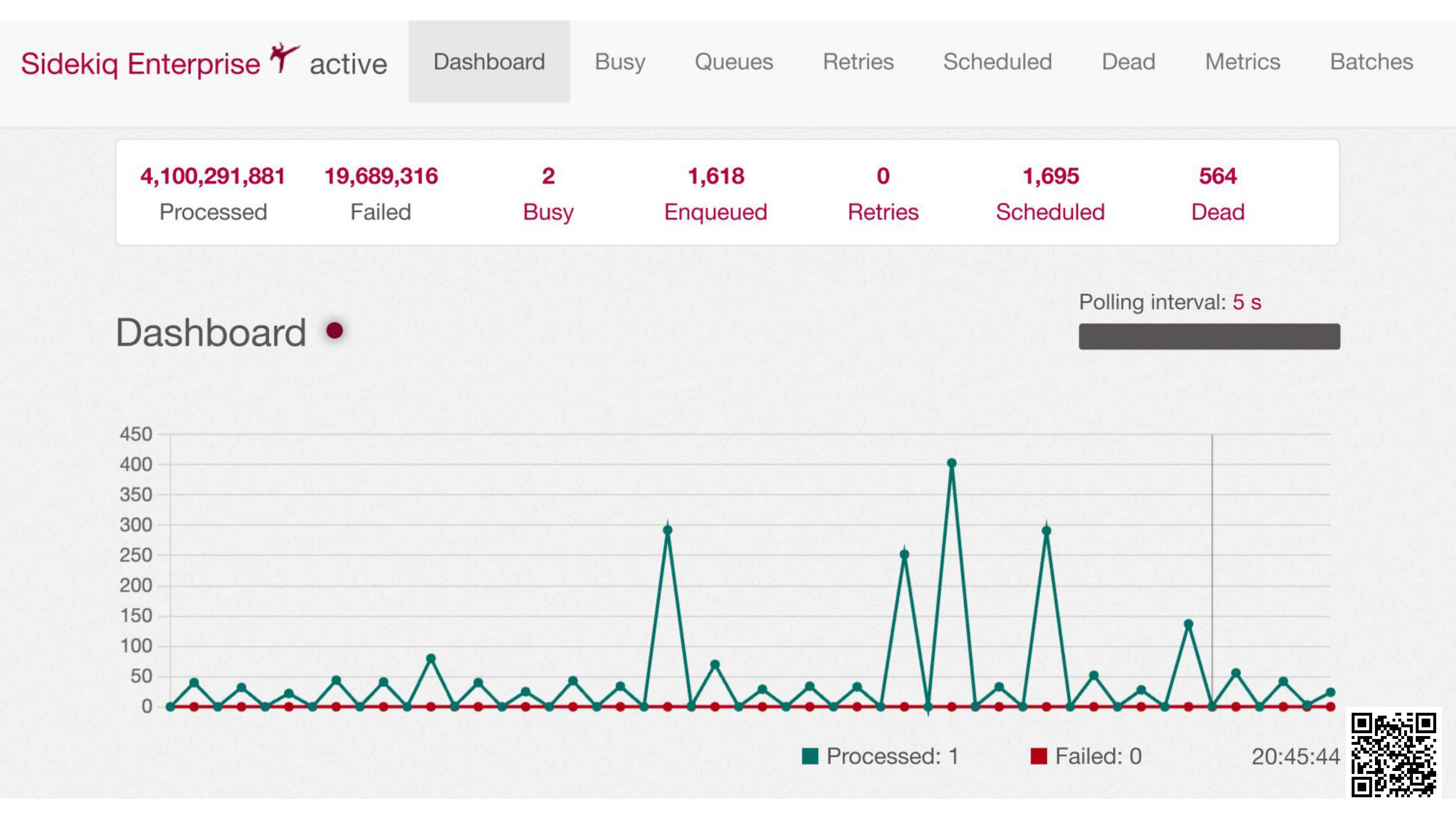
We can see jobs processed… which doesn’t really help us.
At BiggerPockets, we found ourselves in this vicious cycle.
Engineers would deploy ad hoc logging, we would deploy the app and wait for the incident to happen again.
The incident happened… but we didn’t have enough data to resolve it.
We were always on the back foot - always being reactive.
The Solution: Steps to Observable Software
I came up with five simple steps to understand our Rails app better in production.
I call it Steps to Observable Software or SOS.

The steps are:
Question you want answered
Decide the data
Build instrumentation
Use the graphs
Improve
In a later post I’ll detail out these 5 steps.
We've been around the SOS cycle many times at BiggerPockets - and here’s what it gives our team.
Same Outage… With Observability
It's Friday morning this time, not Friday afternoon.
I'm still on call, but I now get a notification from Slack.
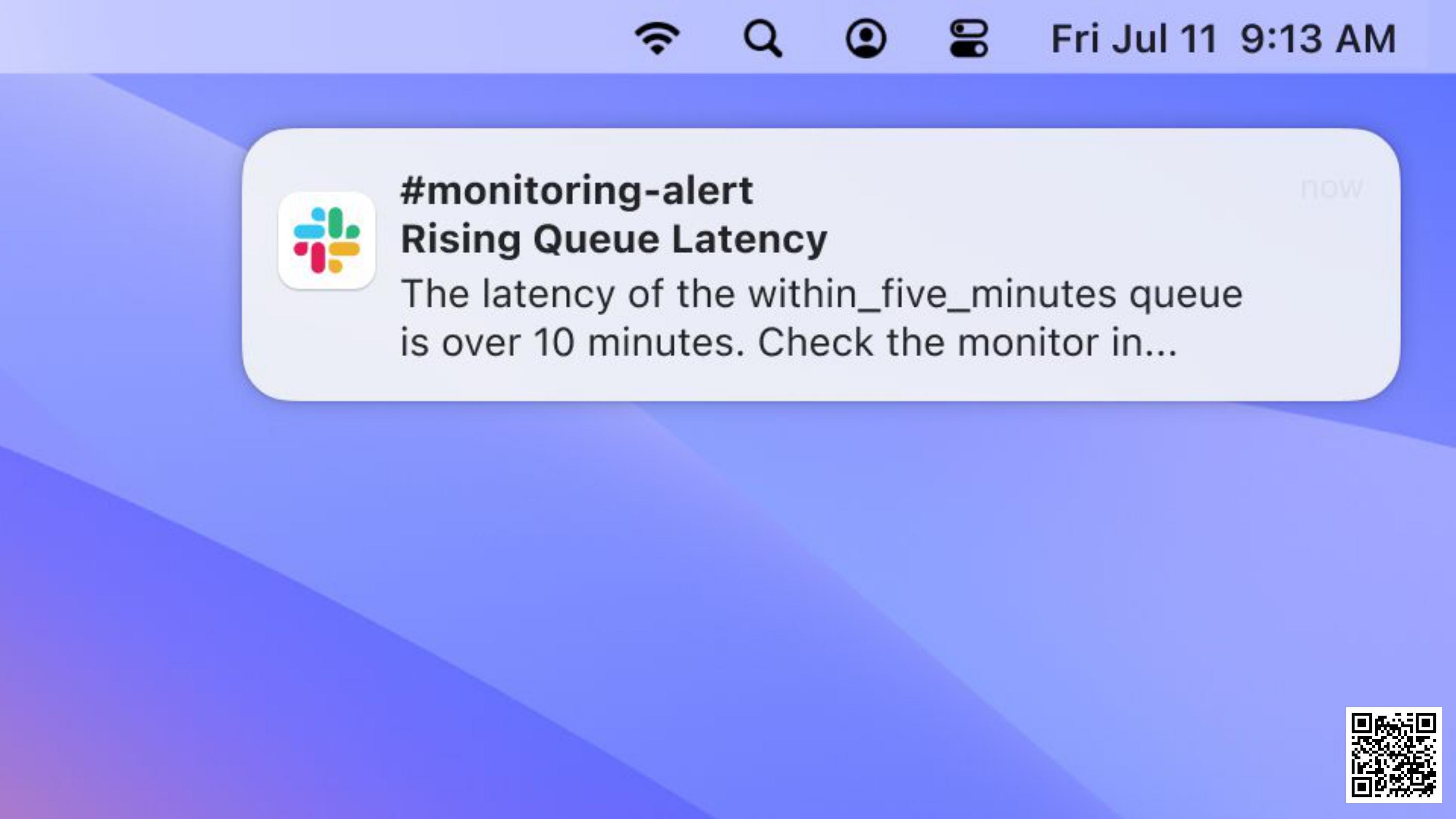
This is not a customer, not somebody in support.
This is our monitoring software telling me the queue has breached it’s agreed queue limit.
This is before any issue has happened. No customer has complained yet.
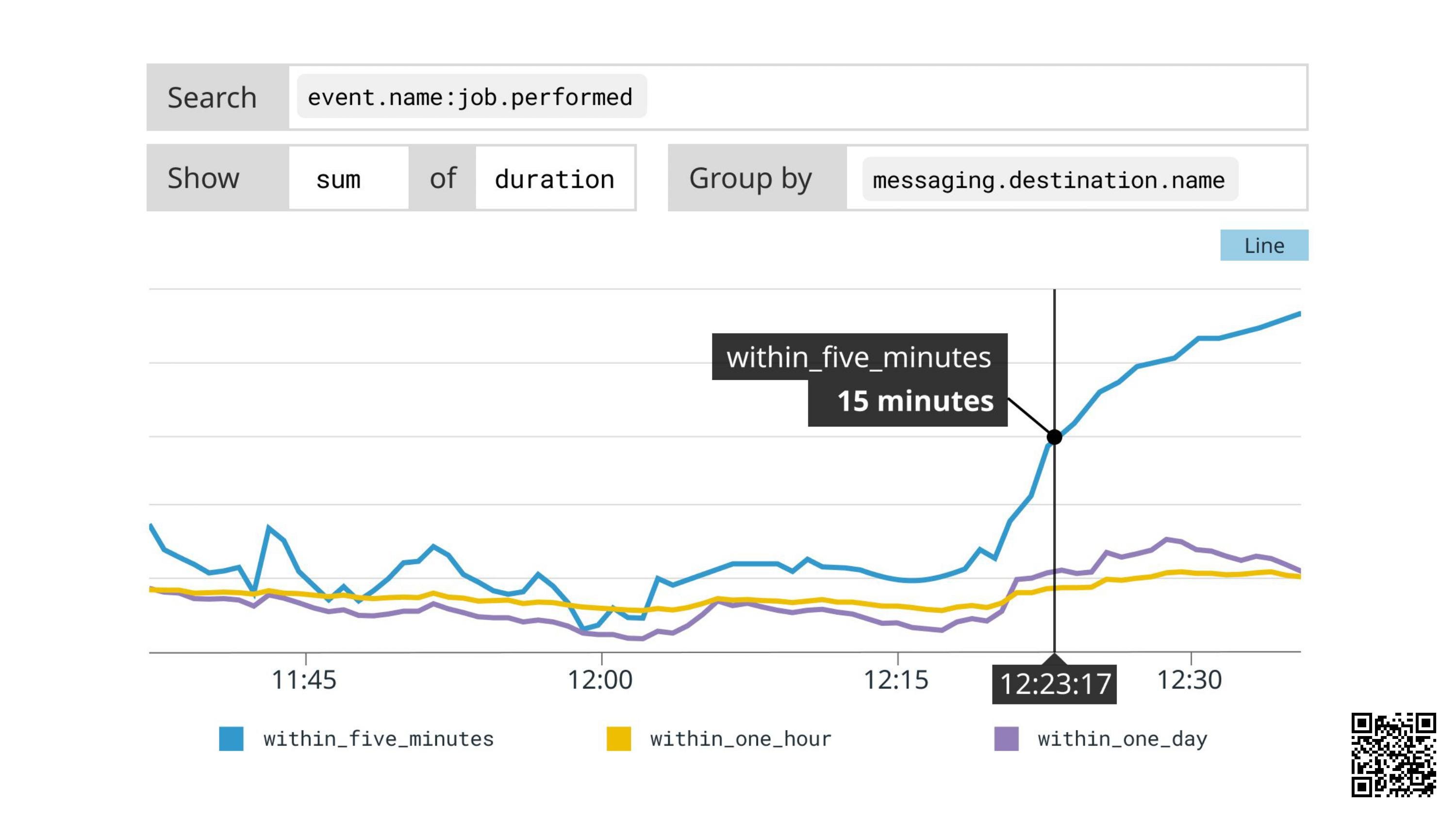
We click the link in the notification and we see this graph:
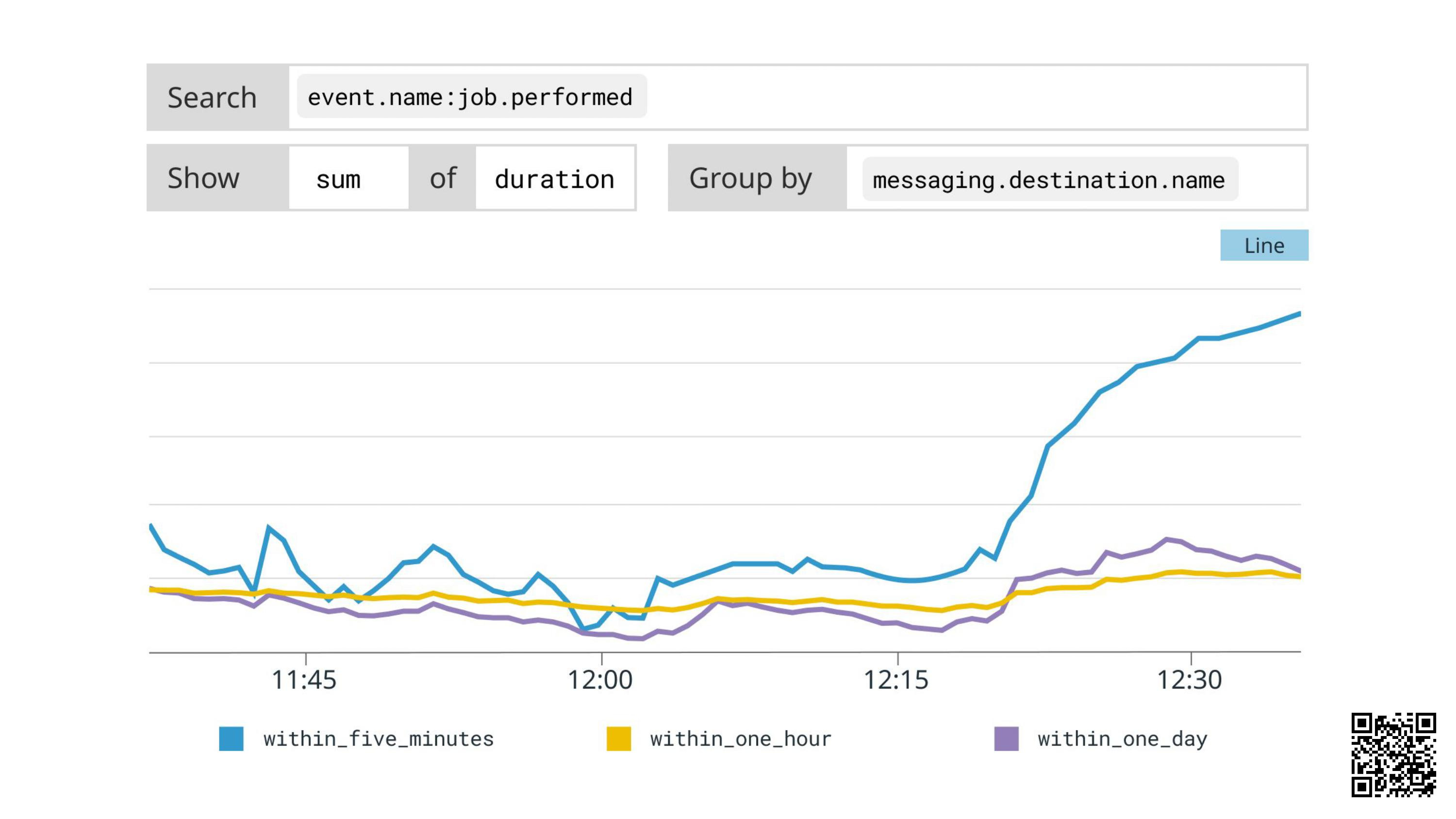
The blue line is rising fast.
Hovering over it, we can see it’s the within_five_minutes queue:
The process starts by asking a question.
Question: Which jobs are taking most time?
We search for job.performed within the same queue, group by code.namespace (job class), sum up the durations and hey presto:
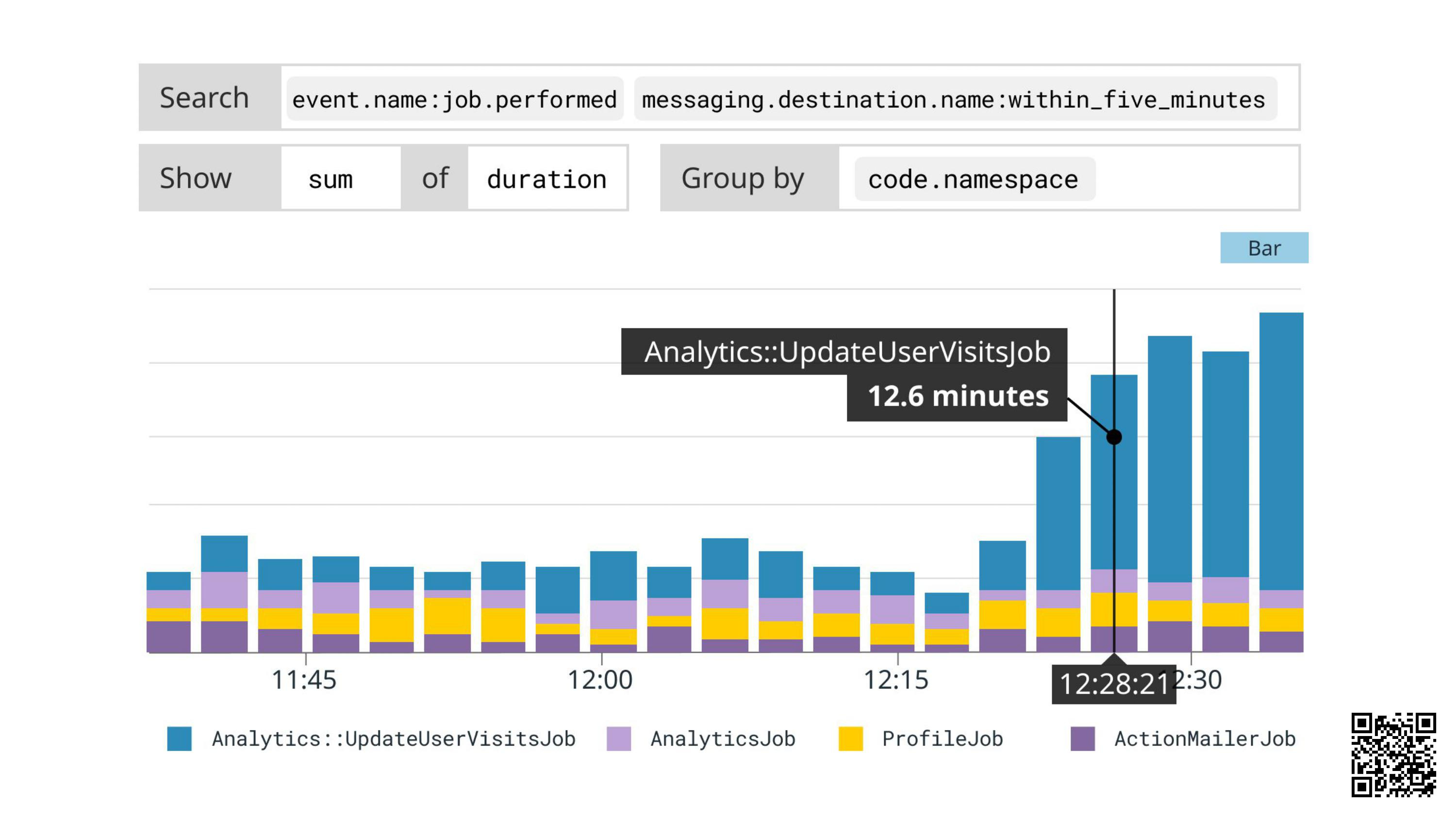
Answer: Analytics::UpdateUserVisitsJob.
Question: What's enqueuing the Analytics::UpdateUserVisitsJob?
We’ll group by http.resource which is a combination of the controller and action:
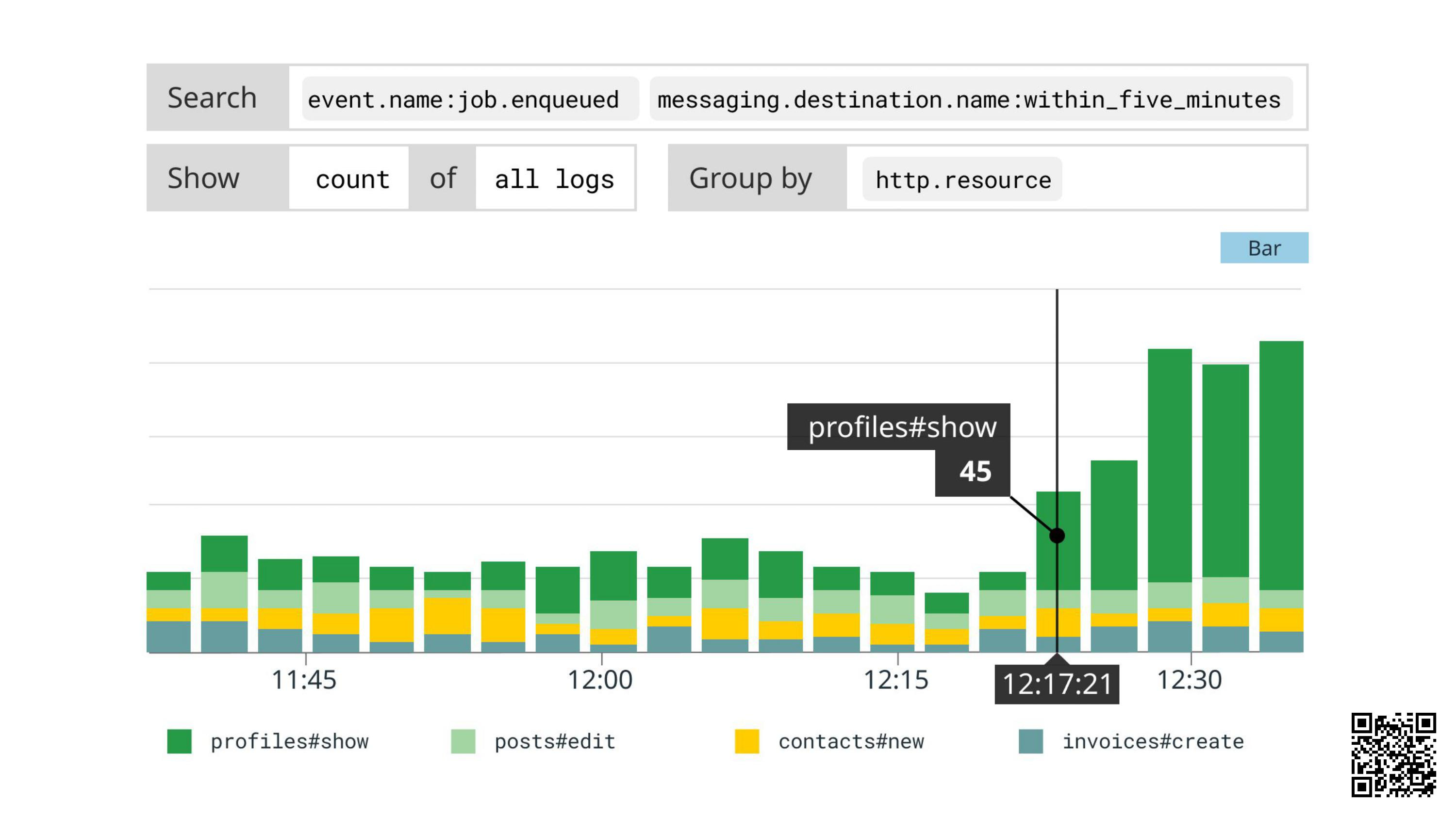
Answer: profiles#show
Question: What IP is hitting this controller?
Let’s group by IP and show as a pie chart:

Answer: 15.145.1.3
We’ve spent less than 5 minutes asking questions of our observability tool and we understand what’s going on.
Let's recap.
A server at 15.145.1.3 is scraping our app
They’re hitting the show action of the profiles controller
This floods the queue with analytics jobs
That delays password reset emails.
The fix
Getting all that data was so quick and easy.
Now we understand what the app is doing, we can block the IP address.
Then go back into the graphs to check on the fix:
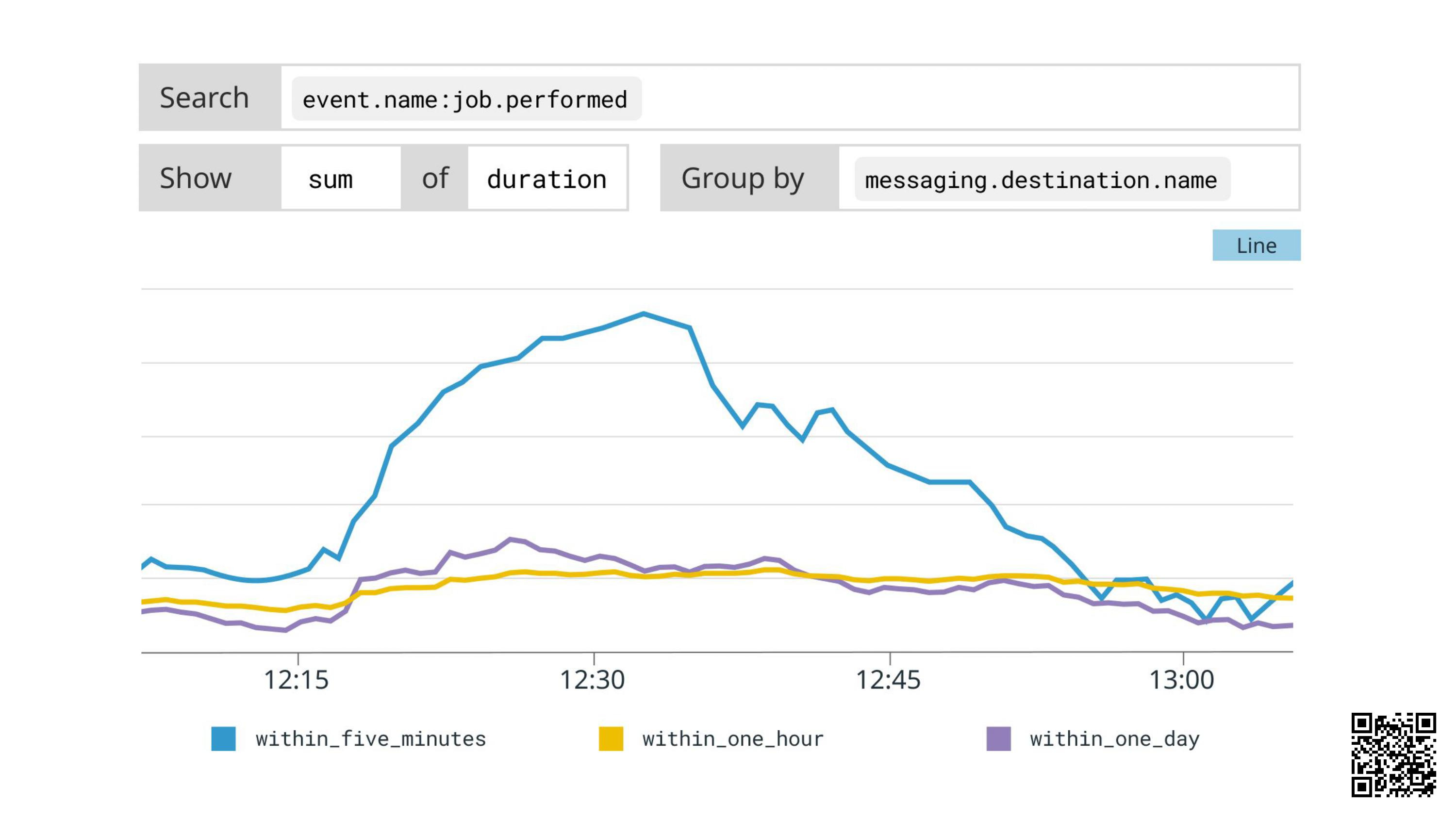
OK! The queue is recovering. Done.
No customer impact. Minimal disruption. Easy to debug. Easy to understand.
Feelings, Revisited
How does this feel?
As an engineer, it feels incredible.
I have the tools to ask any question of my app and get the results in seconds.
I can truly understand my app in production.
With this way of working, I’ve seen a common pattern.
I deploy a feature and I think I know how it’s working.
Then I go to the logs, do some queries, and find out how it’s actually working.
I often find myself thinking “ah… I didn’t expect it to do that…”.
This gets addictive. It also means I start to veer off asking other unrelated questions.
“I wonder why the traffic spikes on a Wednesday at midday?”
“I wonder why the vast majority of users are on iOS at 3am?”
“I wonder why the database keeps timing out?”
Results
Our downtime has dropped by 98% in 18 months.
We fixed 83% of our 500 errors.
Finally, we understand our Rails app in production.
Want Help?
Not every team has these kind of superpowers.
I’m holding a set of group coaching workshops.
$150 for a solo engineer and $2000 for your whole team.
Designed for Senior and Lead Rails Engineers.